Project structure
A Pipecat project will often consist of the following:1. Bot file
E.g.
bot.py. Your Pipecat bot / agent, containing all the pipelines that you
want to run in order to communicate with an end-user. A bot file may take some
command line arguments, such as a transport URL and configuration.2. Bot runner
E.g.
bot_runner.py. Typically a basic HTTP service that listens for incoming
user requests and spawns the relevant bot file in response.You can call these files whatever you like! We use
bot.py and
bot_runner.py for simplicity.Typical user / bot flow
There are many ways to approach connecting users to bots. Pipecat is unopinionated about how exactly you should do this, but it’s helpful to put an idea forward. At a very basic level, it may look something like this:User requests to join session via client / app
Client initiates a HTTP request to a hosted bot runner service.
Bot runner handles the request
Authenticates, configures and instantiates everything necessary for the
session to commence (e.g. a new WebSocket channel, or WebRTC room, etc.)
Bot runner spawns bot / agent
A new bot process / VM is created for the user to connect with (passing
across any necessary configuration.) Your project may load just one bot
file, contextually swap between multiple, or launch many at once.
Bot instantiates and joins session via specified transport credentials
Bot initializes, connects to the session (e.g. locally or via WebSockets,
WebRTC etc) and runs your bot code.
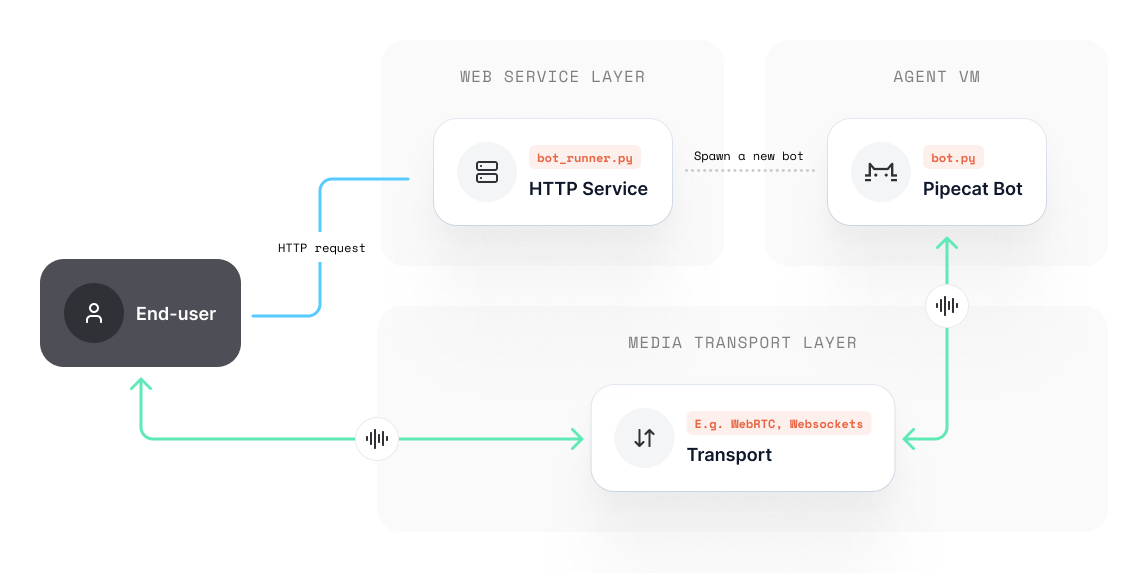
Bot runner
The majority of use-cases require a way to trigger and manage a bot session over the internet. We call these bot runners; a HTTP service that provides a gateway for spawning bots on-demand. The anatomy of a bot runner service is entirery arbitrary, but at very least will have a method that spawns a new bot process, for example:/start_bot/ endpoint which listens for incoming user POST requests or webhooks, then configures the session (such as creating rooms on your transport provider) and instantiates a new bot process.
A client will typically require some information regarding the newly spawned bot, such as a web address, so we also return some JSON with the necessary details.
Data transport
Your transport layer is responsible for sending and receiving audio and video data over the internet. You will have implemented a transport layer as part of yourbot.py pipeline. This may be a service that you want to host and include in your deployment, or it may be a third-party service waiting for peers to connect (such as Daily, or a websocket.)
For this example, we will make use of Daily’s WebRTC transport. This will mean that our bot_runner.py will need to do some configuration when it spawns a new bot:
- Create and configure a new Daily room for the session to take place in.
- Issue both the bot and the user an authentication token to join the session.
Best practice for bot files
A good pattern to work to is the assumption that yourbot.py is an encapsulated entity and does not have any knowledge of the bot_runner.py. You should provide the bot everything it needs to operate during instantiation.
Sticking to this approach helps keep things simple and makes it easier to step through debugging (if the bot launched and something goes wrong, you know to look for errors in your bot file.)
Example
Let’s assume we have a fully service-drivenbot.py that connects to a WebRTC session, passes audio transcription to GPT4 and returns audio text-to-speech with ElevenLabs.
We’ll also use Silero voice activity detection, to better know when the user has stopped talking.
bot.py
HTTP API
To launch this bot, let’s create abot_runner.py that:
- Creates an API for users to send requests to.
- Launches a bot as a subprocess.
bot_runner.py
Dockerfile
Since our bot is just using Python, our Dockerfile can be quite simple:requirements.txt:
requirements.txt
.env file with our service keys
.env
How it works
Right now, this runner is spawningbot.py as a subprocess. When spawning the process, we pass through the transport room and token as system arguments to our bot, so it knows where to connect.
Subprocesses serve as a great way to test out your bot in the cloud without too much hassle, but depending on the size of the host machine, it will likely not hold up well under load.
Whilst some bots are just simple operators between the transport and third-party AI services (such as OpenAI), others have somewhat CPU-intensive operations, such as running and loading VAD models, so you may find you’re only able to scale this to support up to 5-10 concurrent bots.
Scaling your setup would require virtualizing your bot with it’s own set of system resources, the process of which depends on your cloud provider.
Best practices
In an ideal world, we’d recommend containerizing your bot and bot runner independently so you can deploy each without any unnecessary dependencies or models. Most cloud providers will offer a way to deploy various images programmatically, which we explore in the various provider examples in these docs. For the sake of simplicity defining this pattern, we’re just using one container for everything.Build and run
We should now have a project that contains the following files:bot.pybot_runner.pyrequirements.txt.envDockerfile
docker build ... and deploy your container. Of course, you can still work with your bot in local development too: