Two Ways To Build Voice-to-voice
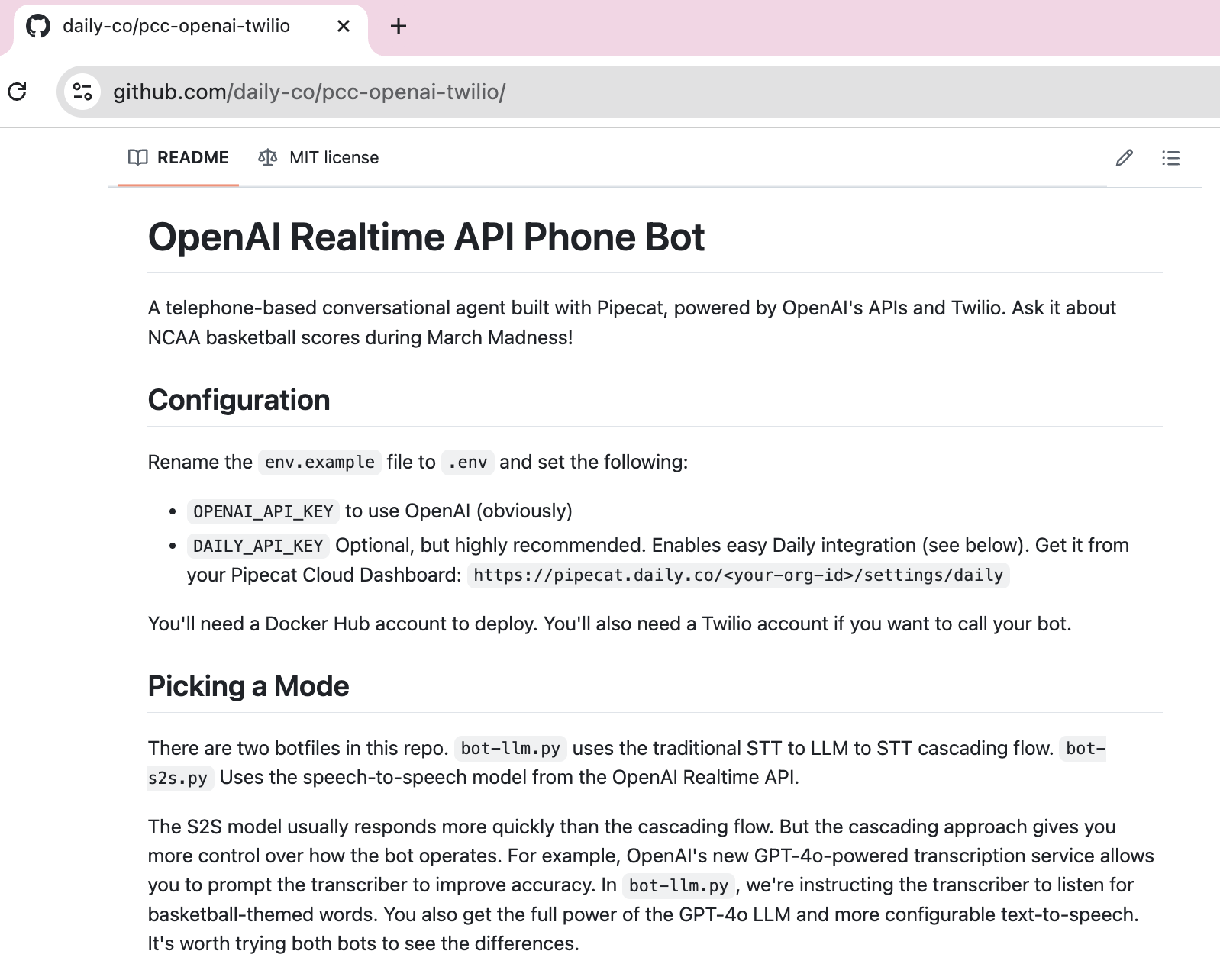
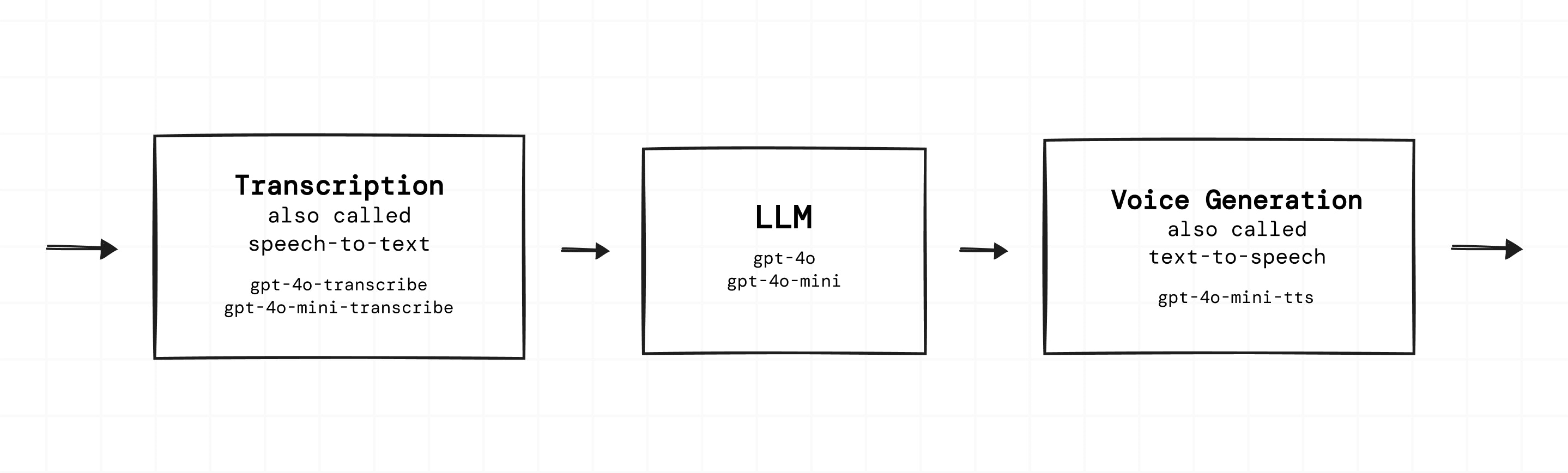
You can build voice-to-voice applications in two ways:- The cascaded models approach, using separate models for transcription, the LLM, and voice generation.
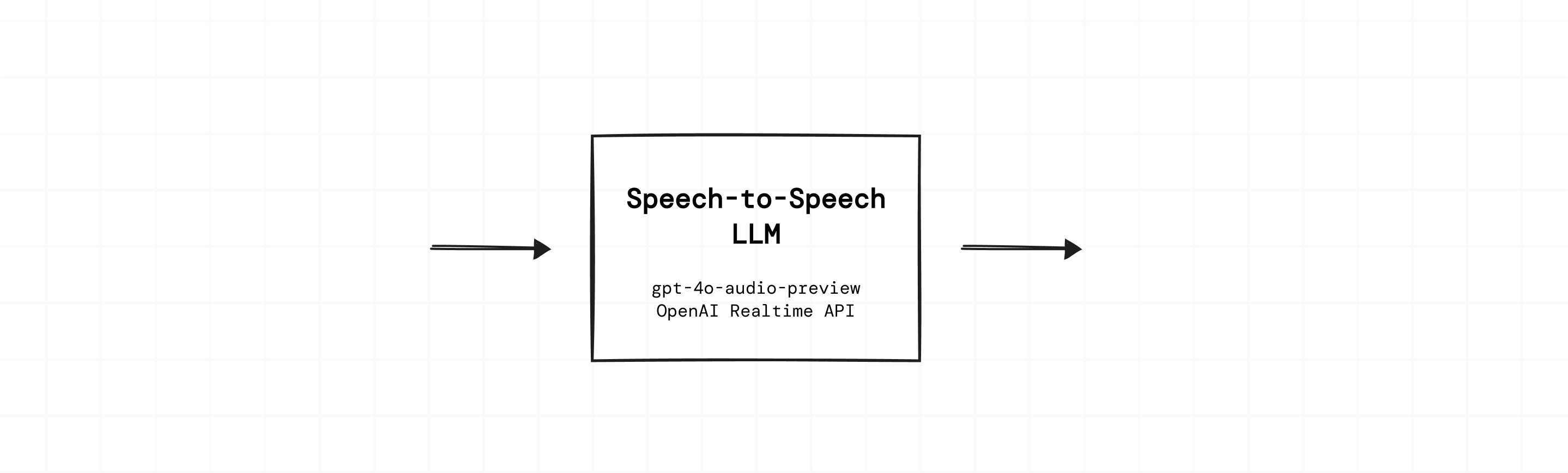
- Using a single, speech-to-speech model. This is conceptually much simpler. Though note that most applications also need to implement things like function calling, retrieval-augmented search, context management, and integration with existing systems. So the core pipeline is only part of an app’s complexity.
- The cascaded models approach is preferable if you are implementing a complex workflow and need the best possible instruction following performance and function calling reliability. The
gpt-4omodel operating in text-to-text mode has the strongest instruction following and function calling performance. - The speech-to-speech approach offers better audio understanding and human-like voice output. If your application is primarily free-form, open-ended conversation, these attributes might be more important than instruction following and function calling performance. Note also that
gpt-4o-audio-previewand the OpenAI Realtime API are currently beta products.
OpenAI Audio Models and APIs
Transcription API
- Models:
gpt-realtime-whisper(default for streaming),gpt-4o-transcribe,gpt-4o-mini-transcribe - Pipecat services:
OpenAISTTService,OpenAIRealtimeSTTService(reference docs) - OpenAI endpoint:
/v1/audio/transcriptions(docs)
Chat Completions API
- Models:
gpt-4o,gpt-4o-mini,gpt-4o-audio-preview - Pipecat service:
OpenAILLMService(reference docs) - OpenAI endpoint:
/v1/chat/completions(docs)
Realtime API
- Models:
gpt-realtime-2,gpt-realtime-1.5,gpt-realtime - Pipecat service:
OpenAIRealtimeLLMService(reference docs) - OpenAI docs (overview)
Speech API
- Models:
gpt-4o-mini-tts - Pipecat service:
OpenAITTSService(reference docs) - OpenAI endpoint:
/v1/audio/speech(docs)
Sample code and starter kits
If you have a code example or starter kit you would like this doc to link to, please let us know. We can add examples that help people get started with the OpenAI audio models and APIs.Single-file examples
OpenAI STT → LLM → TTS
A complete implementation demonstrating the cascaded approach with OpenAI services
OpenAI Realtime API
A speech-to-speech implementation using OpenAI’s Realtime API
OpenAI + Twilio + Pipecat Cloud
This starter kit is a complete telephone voice agent that can talk about the NCAA March Madness basketball tournaments and look up realtime game information using function calls.